5.9、逻辑回归
功能模块如图所示:
逻辑回归训练 ¶
功能:执行多项逻辑回归。在对话框中选择目标列(顶部的组合框),即响应。
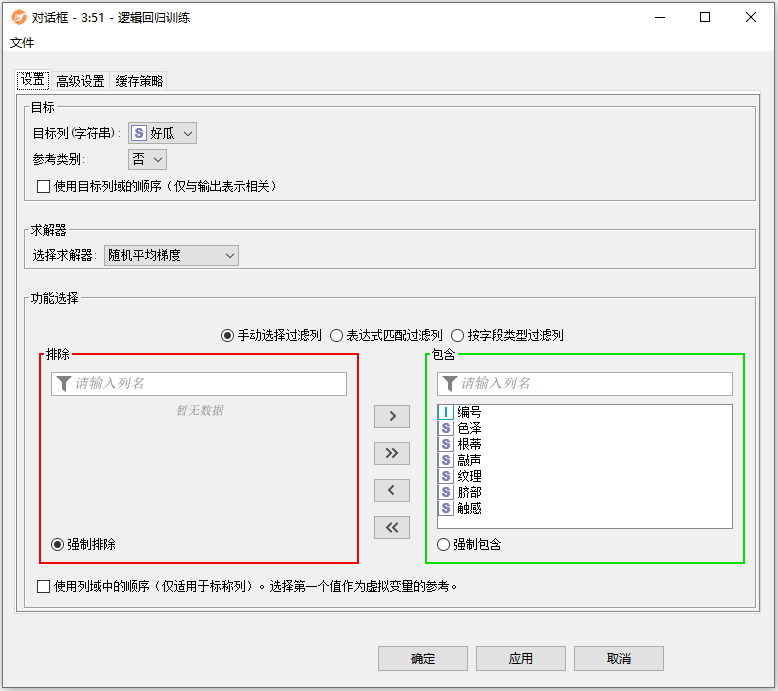
配置界面功能说明:
配置-选项:
- 目标列(字符串):选择目标列。只允许带有名义数据的列。如果目标列的域不可用,则引用类别为空。在这种情况下,节点在计算逻辑回归模型之前确定域值,并选择最后一个域值作为目标参考类别。
- 参考类别:参考类别是指概率为1减去所有其他概率之和的类别。在有两个类的情况下这类通常是你不想显式地对概率建模的类。
- 使用目标列域的顺序:默认情况下,目标域值在输出中按字典顺序排序,但是您可以通过选中复选框来强制保留目标列域的顺序。注:如果在下拉列表中选择了目标参考列,则该复选框将对模型的系数没有影响,除非输出表示形式(例如,系数表中的行顺序)可能会发生变化。
- 求解器:选择要使用的求解器。迭代重加权最小二乘或随机平均梯度。
- 功能选择:指定应该包含在回归模型中的独立列。数字和名义数据可以包括在内。
- 使用列域中的数据:默认情况下,标称值列的域值(类别)是按字典顺序排序的,但您可以检查是否使用了列域的顺序。请注:在创建虚拟变量时,第一个类别被用作参考。
配置-高级设置:
- 求解器选项:
- 延迟执行计算:如果选中,延迟执行。即只有在当前样本中确实存在相应的特征时,系数才会更新。通常比正常版本更快,特别是对于稀疏数据(即对于大多数行大多数值为零的数据)。目前只有SAG求解器支持。
- 计算系数统计:如果选中,该节点将计算系数的标准误差、z-score和P>|z|值。注意,在高斯先验的情况下,这些都受到正则化的影响。如果模型是在许多特性上学习的,那么计算这些统计信息是昂贵的,并且可能负责节点运行时的很大一部分。
- 终止条件:
- 最大周期数:可以指定要执行的最大学习周期数。这是要遍历整个表的次数。这个值在很大程度上决定了学习所需的时间。
- 科学计数法:此值用于确定模型是否聚合。如果所有系数的相对变化都小于,则停止训练。
- 学习率/步长:
- 学习率策略:该策略为优化过程提供了学习率。只对SAG求解器重要。
- 步长:在固定学习率策略的情况下使用的步长(学习率)。
- 调整:
- 权重:系数的权重分布。
- 方差:权重分布的方差。较大的方差对应较少的正则化。
- 数据处理:
- 将数据保存在内存中:如果选择,数据将被读入内部数据结构,从而导致极大的速度提高。如果您有足够的可用内存,特别是如果您使用SAG求解器,则强烈建议使用此选项,因为它们的处理速度高度依赖于对单个样本的随机访问。
- 块大小:如果数据不完全保存在内存中,则节点将数据块读入内存以模拟SAG求解器的随机访问。该参数指定这些块应该有多大。
- 使用种子:检查是否要使用静态种子。如果您使用SAG求解器,建议获得可重复的结果。
- 种子:静态种子使用。点击“随机”按钮生成一个新的种子。
逻辑回归预测 ¶
功能:使用逻辑回归模型预测响应。该节点需要连接到逻辑回归训练节点模型和一些测试数据。只有当测试数据包含训练模型使用的列时,它才可执行。该节点将一个新列追加到包含每行预测的输入表中。
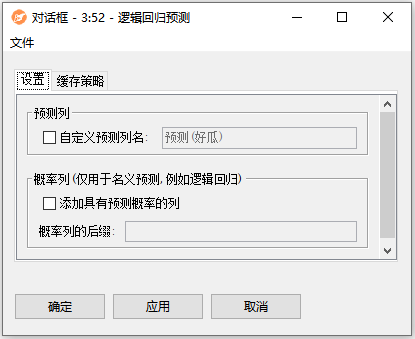
配置界面功能说明:
配置-设置:
- 预测列:选择目标列。可自定义预测列名称。
- 概率列:追加的列数等于目标列的类别数。它们表示输入数据中的一行属于特定类别的概率。