5.3、随机森林
功能模块如图所示:
随机森林训练 ¶
功能:随机森林定义:指的是利用多棵树对样本进行训练并预测的一种分类器。该分类器最早由Leo Breiman和Adele Cutler提出,并被注册成了商标。在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。
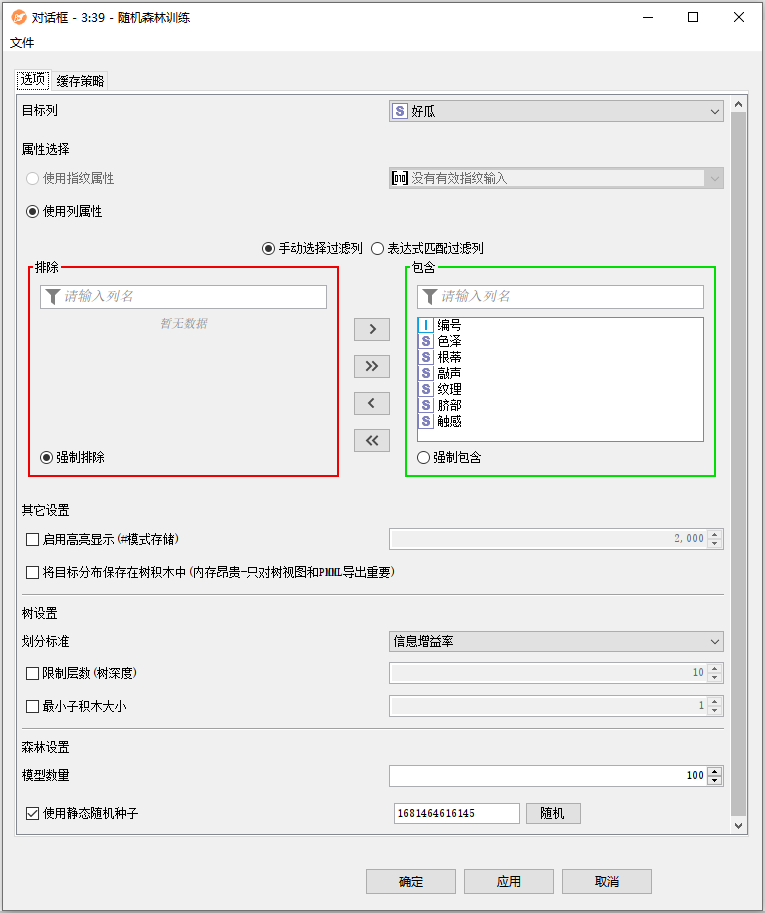
配置界面功能说明:
配置-选项:
- 目标列:选择包含要学习的值的列。在学习过程中,该列中缺少值的行将被忽略。
- 属性选择:选择应该学习模型的属性。有两种模式可供选择。
- 使用指纹属性:使用指纹/向量(可能是位、字节和双精度)列,通过将向量的每个条目作为单独的属性来学习模型(例如,长度为1024的位向量扩展为1024个二进制属性)。节点要求所有向量的长度相同。
- 使用列属性:列属性使用表中的普通列(例如String, Double, Integer等)作为学习模型的属性。对话框允许您手动选择列(通过将它们移动到右侧面板)或通过通配符/正则表达式选择(所有名称与通配符/正则表达式匹配的列都用于学习)。在手动选择的情况下,新列(即在配置节点时不可用的列)的行为可以指定为强制排除(排除新列,因此不用于学习)或强制包含(包括新列,因此用于学习)。
- 其它设置:
- 启用高亮显示(存储模式):如果选中,该节点将存储选定的行数,并在节点视图中突出显示。
- 将目标分布保存在树积木中:如果选中,该模型将存储目标类别值在每个树节点中的分布。存储类分布可能会大大增加内存消耗,因此如果您的用例不需要它,建议不勾选该项。
- 树设置:
- 划分标准:选择这里的分割准则。基尼系数通常是一个很好的选择,用于“分类和回归树”(Breiman et al, 1984)和原始随机森林算法(由Breiman et al, 2001描述);信息增益比通过分裂熵归一化标准信息增益,以克服具有许多子节点的名义分裂的不公平偏好。
- 限制层数(树深度):要学习的树的层数。例如,值1只会分割(单个)根节点,从而产生决策桩。
- 最小子节点大小:子节点中的最小记录数。在原始论文中,它被设置为1,这确保了每棵学习到的树都完美地适合它的训练数据(也就是说,如果它不包含具有不同标签的等效行)。
- 森林设置:
- 模型数量:要学习的决策树的数量。对于大多数数据集,100到500之间的值会产生良好的结果,但最佳数字取决于数据。
- 使用静态随机种子:选择一种种子以获得可重复的结果。
随机森林预测 ¶
功能:根据随机森林模型中单个树的预测的聚合来预测模式。
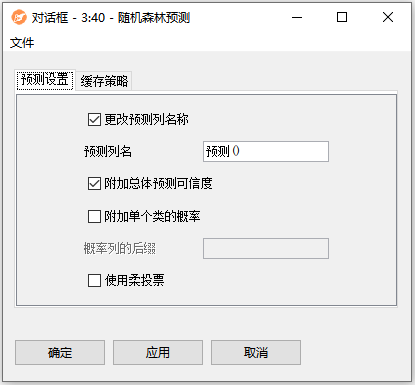
配置界面功能说明:
配置-预测设置:
- 更改预测列名称:如果要更改包含预测的列的名称,可勾选此项,并自定义设置修改后的列名称。
- 附加总体预测可信度:预测类别的可信度。它是所有可信度值中的最大值(可以单独追加)。
- 附加单个类的概率:每个类的预测可信度。它是预测到当前类的树的数量(每个列名)除以树的总数。
- 概率列的后缀:勾选"附加单个类的概率"后,这里可以自定义输入类概率列名称的后缀名称。
- 使用柔投票:在默认情况下(“硬投票”),预测得到最多选票的类别。而在“软投票”的情况下,对所有树的类概率进行聚合,并预测聚合概率最高的类。为了使其正常工作,随机森林模型需要包含类分布。这可以通过选择“将目标分布保存在树积木中”选项在随机森林预测积木节点中指定。在没有保存目标分布的模型上设置此选项,将导致发出警告消息。