5.2、决策树
功能模块如图所示:
决策树训练 ¶
功能:该节点在主存储器中归纳出一个分类决策树。目标属性必须是标称的。用于决策的其他属性可以是名义属性,也可以是数字属性。数值分割总是二进制的(两个结果),在一个分割点将域划分为两个分区。名义分割可以是二元(两个结果),也可以有与名义值一样多的结果。在二进制分割的情况下,标称值被划分为两个子集。该决策树实现中使用的大多数技术可以在J.R.Quinlana的“C4.5机器学习程序”和J.R.的“SPRINT:数据挖掘的可扩展并行分类器”中找到。
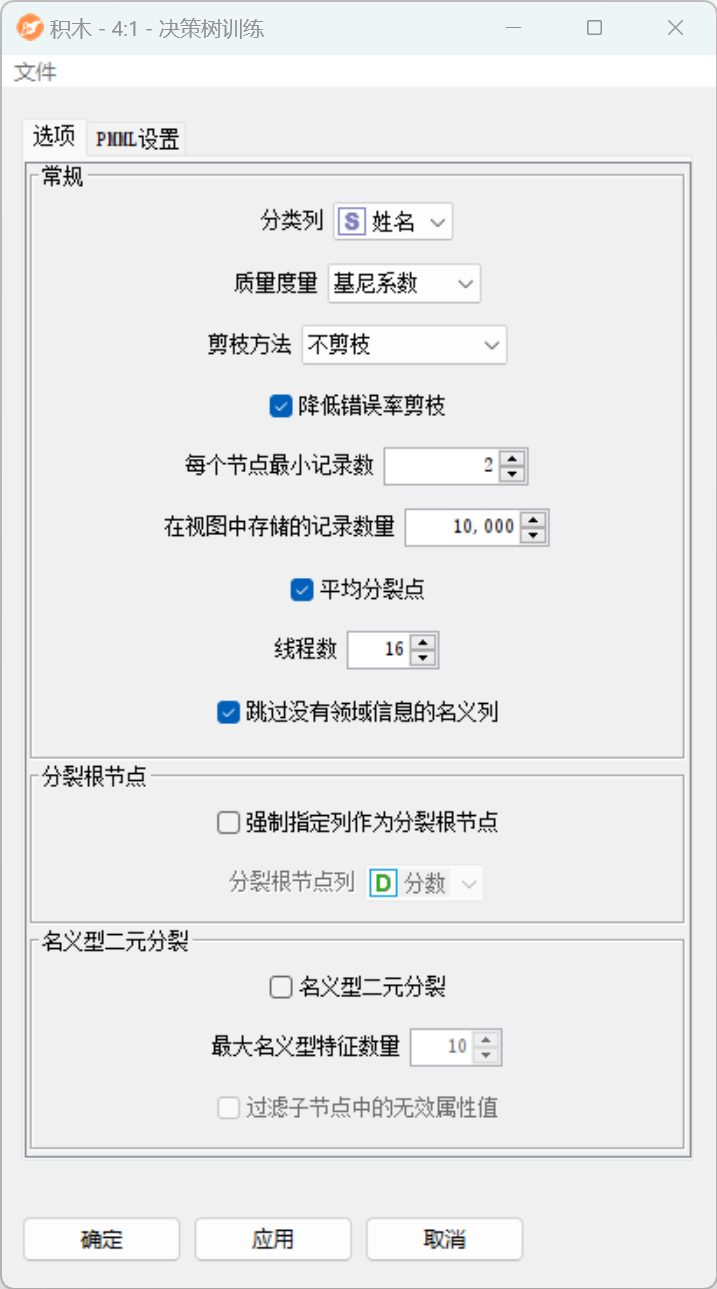
配置界面功能说明:
配置-选项:
- 常规:
- 分类列:选择目标属性。只允许使用名义属性。
- 质量度量:选择用于计算拆分的质量度量。可用的是“基尼系数”和“信息增益率”。
- 剪枝方法:修剪树的大小,避免过拟合,提高泛化性能,从而提高预测质量(对于预测,请使用“决策树预测”节点)。
- 降低错误率剪枝:如果选中(默认),则在后处理步骤中使用一种简单的修剪方法来修剪树:从叶子开始,每个节点都会替换其最流行的类,但前提是预测精度不会降低。减少错误修剪具有简单和快速的优点。
- 每个节点最小记录数:选择每个节点中至少需要的最小记录数。如果记录的数量小于或等于此数量,则树不再生长。这对应于一个停止标准(预修剪)。
- 在视图中存储的记录数量:为视图选择存储在树中的记录数。这些记录是启用高亮显示所必需的。
- 平均分裂点:如果选中(默认),则根据分隔两个分区的两个属性值的平均值来确定数字属性的拆分值。如果未选中,拆分值将设置为较低分区的最大值(如C4.5)。
- 线程数:此节点可以利用多个线程,从而利用多个处理器或内核。这可以提高性能。默认值设置为DataBeam可用的处理器或内核数。如果设置为1,则按顺序执行该算法。
- 跳过没有领域信息的名义列:如果选中,则跳过不包含域值信息的名义列。
- 分裂根节点:
- 强制指定列作为分裂根节点:如果选中,则在所选列上计算第一个拆分,而不评估任何其他列的可能拆分。如果所选列不包含有效的拆分(例如,因为它在所有行中都是常数值),则会显示一条警告消息。如果不确定,请保持未选中状态。
- 名义型二元分裂:
- 名义型二元分裂:如果选中,则以二进制方式拆分标称属性。二元分裂更难计算,但也会产生更准确的树。标称值分为两个子集(每个子集一个子集)。如果未选中,则为每个标称值创建一个子项。
- 最大名义型特征数量:二进制标称分裂的子集很难计算。为了找到n个标称值的最佳子集,必须进行2^n次方计算。因此,可以定义最大数量的值,为其计算所有可能的子集。在该阈值以上,应用启发式算法,该启发式算法首先计算第二分区的最佳标称值,然后计算第二最佳值,以此类推;直到结束。
- 过滤子节点中的无效属性值:启用此选项将对树进行后处理并过滤无效检查。
决策树预测 ¶
功能:此节点使用现有的决策树来预测新模式的类值。
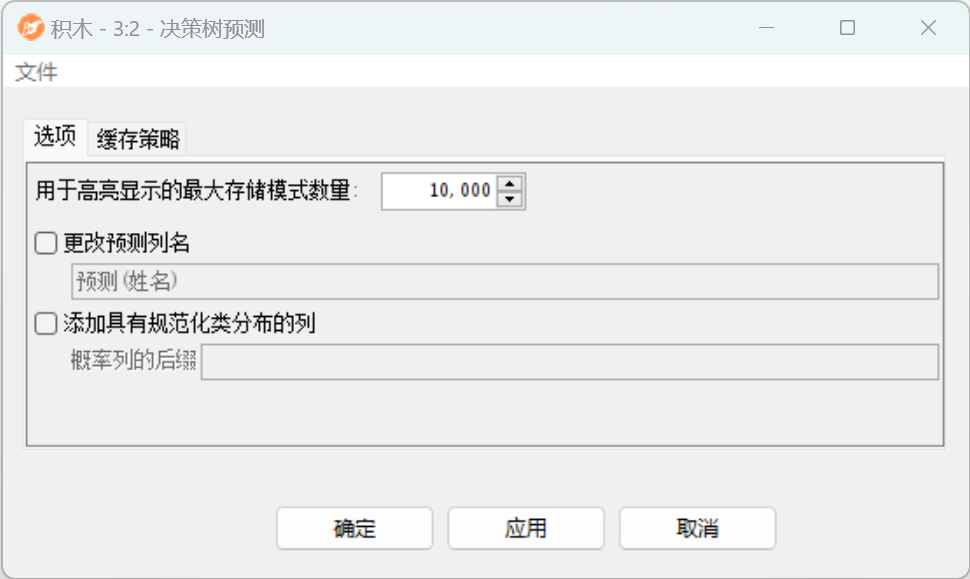
配置界面功能说明:
配置-选项:
- 用于高亮显示的最大存储模式数量:确定树将存储的支持高亮的最大模式数量。
- 更改预测列名:勾选此项,可以更改预测列的名称。
- 添加具有规范化类分布的列:显示每个预测的归一化类分布。规范化分布列的后缀,它的名称类似于:P(trainingColumn=value)。