5.10、GBDT
功能模块如图所示:
GBDT训练(分类) ¶
功能:学习以分类为目标的梯度增强树。该算法使用非常浅的回归树和一种特殊形式的增强来构建树的集合。该节点允许执行行抽样(bagging)和属性抽样(attribute bagging)。如果使用抽样,这通常被称为随机梯度增强树。
配置界面功能说明:
配置-选项:
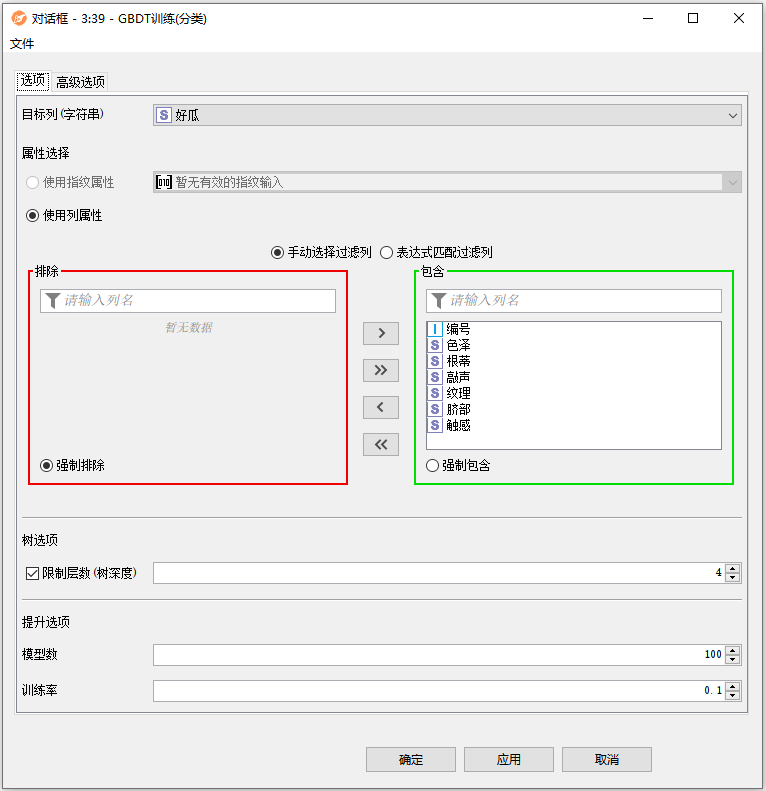
- 目标列(字符串):选择包含要学习的值的列。在学习过程中,该列中缺少值的行将被忽略。除了标称列,该节点还支持概率分布列作为目标。
- 属性选择:选择应该学习模型的属性。有两种模式可供选择。
- 使用指纹属性:指纹属性使用指纹/向量(可能是位,字节和双精度)列,通过将向量的每个条目作为单独的属性来学习模型(例如,长度为1024的位向量被扩展为1024个二进制属性)。节点要求所有向量的长度相同。
- 使用列属性:列属性使用表中的普通列(例如String, Double, Integer等)作为学习模型的属性。对话框允许手动选择列(通过将它们移动到右侧面板)或通过通配符/正则表达式选择(所有名称与通配符/正则表达式匹配的列都用于学习)。在手动选择的情况下,新列(即在配置节点时不可用的列)的行为可以指定为强制排除(排除新列,因此不用于学习)或强制包含(包括新列,因此用于学习)。
- 限制层数(树深度):要学习的树的层数。例如,值1将分割(单个)根节点(单层决策树)。对于梯度提升树,深度通常在4到10之间就足够了。较大的树将很快导致过拟合。
- 模型数:需要学习的决策树的数量。对于目标类别值很少的小数据集,一个“合理”的值可以是非常少(比如10)到数千。与随机森林算法不同,梯度提升树在模型数量设置过高且学习率不够低时,容易出现过拟合现象。
- 训练率:学习率影响单个模型对集成结果的影响程度。通常0.1是一个不错的起点,但最佳学习率还取决于模型的数量。集成包含的模型越多,学习率就越低。致过拟合。
配置-高级选项:
- 使用中点分割:用于数值分割两个类边界之间的中点。如果未选择,则分割属性值是具有"<="关系的较小值。
- 对名义列使用二进制拆分:如果选中此选项(默认),则名义列将使用基于集合的拆分以二进制方式进行拆分。如果不勾选此选项,算法将为名义列的每个可能值生成一个子节点。
- 缺失值处理:这里可以指定首选的缺失值处理,有以下两个选项。
- XGBoost:如果选中了(也是默认值),learner将通过将缺失值发送到分割的每个方向来计算哪个方向最适合丢失值。产生最佳结果(即最大增益)的方向将被用作缺失值的默认方向。这种方法对二元和多路拆分都适用。
- Surrogate:该方法计算出了与最佳划分最接近的每个划分方案。注:此方法只能用于二元名词性拆分。
- 数据采样(行):对行进行采样也称为bagging,是一种非常流行的集成学习策略。对每个个体树的数据行进行采样:如果不启用,每个树学习器将获得完整的数据集,否则每个树将使用不同的数据样本进行学习。选择“有替换”的数据比例为1(=100%)的数据称为自助法(bootstrapping)。对于足够大的数据集,这个bootstrap样本包含与输入数据大约⅔不同的数据行,其中一些数据行被重复多次。
- 属性采样(列):属性抽样也称为随机子空间方法或属性bagging。它最著名的应用是随机森林,但它也可以用于梯度提升树。该选项指定样本大小:
- 所有列(无采样):每个样本由所有列组成,这些列对应于根本不抽样。
- 样本(平方根):以属性总数的平方根作为样本大小。这种方法通常用于随机森林。
- 样本(线性比例):使用属性总数中指定的线性分数作为样本量。0.5的线性分数对应使用所有属性的50%。
- 样本(绝对值):使用指定的数字作为样本大小。
- 属性选择:在这个上下文中,属性选择指的是对属性进行采样的规模(每个树vs.每个树节点)。注:这仅在启用属性采样时生效。
- 对整个树使用相同的属性集:使用此选项,属性将对每棵树进行采样。这意味着我们绘制一个属性样本,并使用它来学习单个树,以便该树的每个节点都看到相同的属性。
- 为每个树节点使用不同的属性集:该策略为每个树节点绘制一个新的属性样本。随机森林通常使用这种策略来使树木更加多样化。(注意,多样性对于梯度增强树并不重要,所以效果不会那么大)。
- 使用静态随机种子:选择一种种子以获得可重复的结果。
GBDT预测(分类) ¶
功能:使用梯度增强树模型对数据进行分类。
配置界面功能说明:
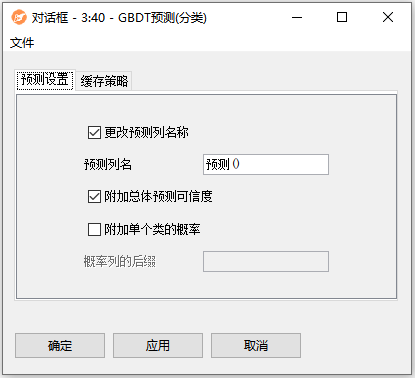
配置-预测设置:
- 更改预测列名称:如果要为包含预测的列使用自定义名称,请选中此选项。
- 附加总体预测可信度:附加一个列,该列包含关于模型如何确定其预测的信息。
- 附加单个类的概率:为每个可能的类追加一个列,其中包含给定行是该类元素的概率。
- 概率列的后缀:允许为概率列添加后缀。
GBDT训练(回归) ¶
功能:以回归为目标学习梯度提升树。该算法使用非常浅的回归树和特殊形式的boosting来构建树的集合。在回归树中,叶节点的预测值是叶节点中记录的平均目标值。因此,如果叶节点内目标值的方差最小,则预测是最好的(相对于训练数据)。这是通过将每个子节点的误差平方和最小化来实现的。
配置界面功能说明:
配置-选项:
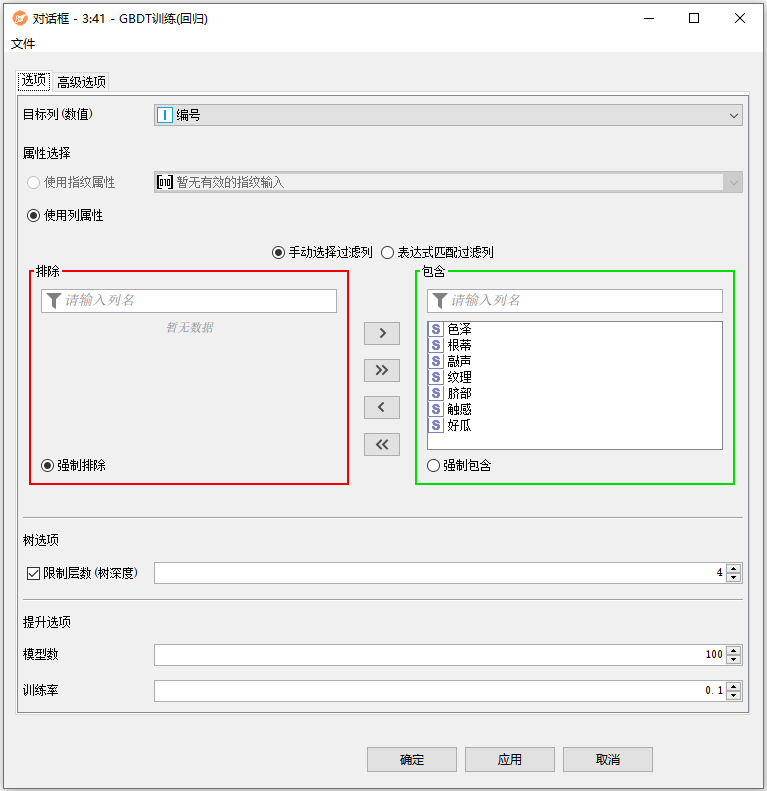
- 目标列(数值):选择包含要学习的值的列。在学习过程中,这一列中有缺失值的行将被忽略。
- 属性选择:选择应该学习模型的属性。有两种模式可供选择。
- 使用指纹属性:指纹属性使用指纹/向量(可能是位,字节和双精度)列,通过将向量的每个条目作为单独的属性来学习模型(例如,长度为1024的位向量被扩展为1024个二进制属性)。节点要求所有向量的长度相同。
- 使用列属性:列属性使用表中的普通列(例如String, Double, Integer等)作为学习模型的属性。对话框允许手动选择列(通过将它们移动到右侧面板)或通过通配符/正则表达式选择(所有名称与通配符/正则表达式匹配的列都用于学习)。在手动选择的情况下,新列(即在配置节点时不可用的列)的行为可以指定为强制排除(排除新列,因此不用于学习)或强制包含(包括新列,因此用于学习)。
- 限制层数(树深度):要学习的树的层数。例如,值1将分割(单个)根节点(单层决策树)。对于梯度提升树,深度通常在4到10之间就足够了。较大的树将很快导致过拟合。
- 模型数:需要学习的决策树的数量。对于目标类别值很少的小数据集,一个“合理”的值可以是非常少(比如10)到数千。与随机森林算法不同,梯度提升树在模型数量设置过高且学习率不够低时,容易出现过拟合现象。
- 训练率:学习率影响单个模型对集成结果的影响程度。通常0.1是一个不错的起点,但最佳学习率还取决于模型的数量。集成包含的模型越多,学习率就越低。致过拟合。
配置-高级选项:
- 使用中点分割:用于数值分割两个类边界之间的中点。如果未选择,则分割属性值是具有"<="关系的较小值。
- 对名义列使用二进制拆分:如果选中此选项(默认),则名义列将使用基于集合的拆分以二进制方式进行拆分。如果不勾选此选项,算法将为名义列的每个可能值生成一个子节点。
- 缺失值处理:这里可以指定首选的缺失值处理,有以下两个选项。
- XGBoost:如果选中了(也是默认值),learner将通过将缺失值发送到分割的每个方向来计算哪个方向最适合丢失值。产生最佳结果(即最大增益)的方向将被用作缺失值的默认方向。这种方法对二元和多路拆分都适用。
- Surrogate:该方法计算出了与最佳划分最接近的每个划分方案。注:此方法只能用于二元名词性拆分。
- 数据采样(行):对行进行采样也称为bagging,是一种非常流行的集成学习策略。对每个个体树的数据行进行采样:如果不启用,每个树学习器将获得完整的数据集,否则每个树将使用不同的数据样本进行学习。选择“有替换”的数据比例为1(=100%)的数据称为自助法(bootstrapping)。对于足够大的数据集,这个bootstrap样本包含与输入数据大约⅔不同的数据行,其中一些数据行被重复多次。
- 属性采样(列):属性抽样也称为随机子空间方法或属性bagging。它最著名的应用是随机森林,但它也可以用于梯度提升树。该选项指定样本大小:
- 所有列(无采样):每个样本由所有列组成,这些列对应于根本不抽样。
- 样本(平方根):以属性总数的平方根作为样本大小。这种方法通常用于随机森林。
- 样本(线性比例):使用属性总数中指定的线性分数作为样本量。0.5的线性分数对应使用所有属性的50%。
- 样本(绝对值):使用指定的数字作为样本大小。
- 属性选择:在这个上下文中,属性选择指的是对属性进行采样的规模(每个树vs.每个树节点)。注:这仅在启用属性采样时生效。
- 对整个树使用相同的属性集:使用此选项,属性将对每棵树进行采样。这意味着我们绘制一个属性样本,并使用它来学习单个树,以便该树的每个节点都看到相同的属性。
- 为每个树节点使用不同的属性集:该策略为每个树节点绘制一个新的属性样本。随机森林通常使用这种策略来使树木更加多样化。(注意,多样性对于梯度增强树并不重要,所以效果不会那么大)。
- 使用静态随机种子:选择一种种子以获得可重复的结果。
GBDT预测(回归) ¶
功能:应用从梯度增强树模型回归。
配置界面功能说明:
配置-预测设置:
- 更改预测列名称:如果要为包含预测的列使用自定义名称,请选中此选项。
- 预测列名:包含预测的输出列的名称。