5.1、预处理
功能模块如图所示:

数据分区 ¶
功能:输入表被分成两个分区(即行),例如训练数据和测试数据。这两个分区在两个输出端口上可用。
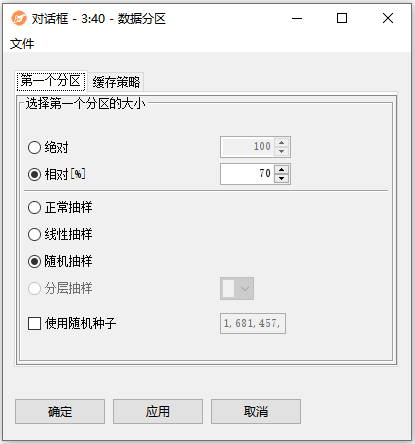
配置界面功能说明:
配置-第一个分区:
- 绝对:指定第一个分区中的绝对行数。如果数据行数少于此处设置的行数,则将所有行输入到第一个表中,而第二个表不包含任何行。
- 相对[%]:输入表中第一个分区中的行数占总行数的百分比。设置的数字必须在0到100之间。
- 正常抽样:这种模式将最上面的行放入第一个输出表中,其余行放入第二个输出表中。
- 线性抽样:这种模式总是包括第一行和最后一行,并在整个表中线性地选择剩余的行(例如,每隔三行)。这对于在保持最小值和最大值的同时对已排序的列进行下采样非常有用。
- 随机抽样:随机采样所有行,你可以选择使用随机种子。
- 分层抽样:选择此模式,即所选列的值分布(大约)保留在输出表中。你可以选择指定字段,作为随机种子。
- 使用随机种子:如果选择随机抽样或分层抽样,您可以在这里输入一个固定的种子,以便在重新执行时获得可重复的结果。如果您没有指定一个种子,那么每次执行都会获取一个新的随机种子。
自动分箱 ¶
功能:该节点允许按间隔对数值数据进行分组——称为分箱。容器有两个命名选项和两个方法,用于定义容器中值的数量和范围。
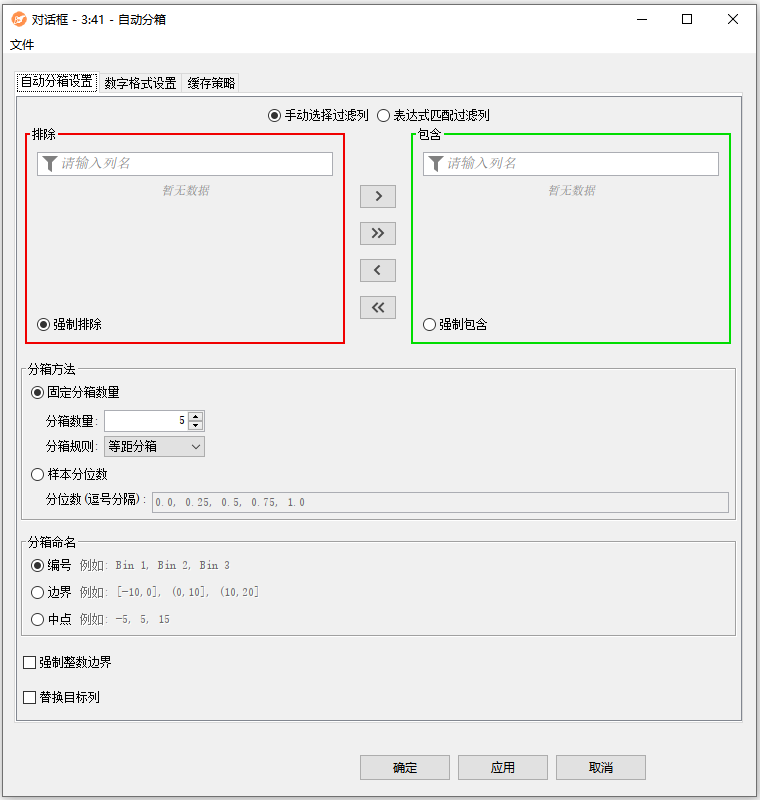
配置界面功能说明:
配置-自动分箱设置:
- 列选择:包含列表中的列被单独处理。排除列表中的列被节点排除。
- 分箱方法:
- 固定分箱数量:对于域范围内宽度相等的箱子或元素出现频率相等的箱子使用固定数量的箱子。
- 样本分位数:使用样本分位数生成对应于给定概率列表的箱子。最小的元素对应的概率为0,最大的元素对应的概率为1。
- 分箱命名:
- 编号:使用前缀为“Bin”的整数标记的箱子,使用“编号”。
- 边界:对于使用区间间隔符号的箱子,使用“边界”。
- 中点:对于显示间隔中点的箱子,使用“中点”。
- 强制整数边界:强制间隔的边界为整数。小数界将被转换,以便第一个区间的下界将是最低值的下限,最后一个区间的上界将是最高值的上限。分隔间隔的边将是小数点边的上限。重复的边将被删除。
- 替换目标列:如果设置,则包含列表中的列将被bin ID列替换。
- 数字格式设置:
- 高级格式:如果启用,箱子中的double格式可以通过该选项卡中的选项配置。
- 输出格式:指定输出格式。数字0.00000035239将显示为3.52E-7(标准字符串)、0.000000352(普通字符串(无指数))和352E-9(工程字符串)。
- 精度:要四舍五入的双精度值的比例。如果比例缩小,则应用指定的舍入模式。
- 精度模式:值舍入后的精度类型。小数点后,默认选项舍入到指定的小数位。而有效数字舍入到有效位数。
- 舍入模式:舍入模式,当double值舍入时应用。舍入模式指定舍入行为。七种不同的舍入模式可供选择:
- UP:舍入模式,舍入值为0。
- DOWN:舍入模式,舍入到零。
- CEILING:舍入模式,舍入到正无穷大。
- FLOOR:舍入模式,为向负无穷舍入。
- HALF_UP:舍入模式,向最邻近的值舍入。若两个最邻近的值距离相等,在这种情况下向上舍入。
- HALF_DOWN:舍入模式,向最邻近的值舍入。若两个最邻近的值距离相等,在这种情况下向下舍入。
- HALF_EVEN:舍入模式,向最邻近的值舍入。若两个最邻近的值距离相等,在这种情况下,舍入到相邻的偶数。
数据归一化 ¶
功能:该节点规范化所有(数字)列的值。

配置界面功能说明:
配置-设置:
- 通过最大最小值线性变换:对所有值进行线性变换,使每列中的最小值和最大值为给定值。
- Z分数归一化(高斯):线性变换,使得每列中的值都是高斯-(0,1)分布的,即均值为0.0,标准差为1.0。
- 通过十进制缩放标准化:一列中的最大值(正负)用j乘以10,直到其绝对值小于或等于1。然后将列中的所有值除以10的j次方。