3.1、行处理
功能模块如图所示:
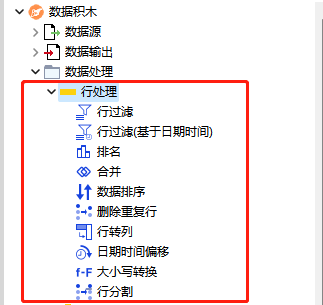
行过滤 ¶
功能:该节点允许用户根据自定义条件进行行过滤。
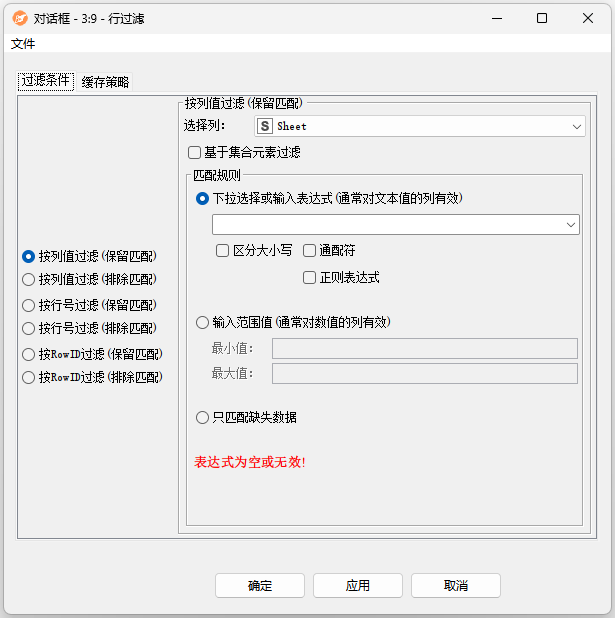
配置界面功能说明:
设置:根据条件保留或排除行。
- 选择保留匹配或排除匹配规则:必选项,选择左侧过滤规则,根据所选的条件选择是否包含或排除行。根据选择的不同,调整右边面板中的过滤器参数。
- 列值匹配:如果选择“按列值过滤”,则选择需要匹配的列的名称。如果所选列是一个集合列,则基于集合元素的筛选器选项允许基于集合的元素而不是其字符串表示来筛选每一行。然后,输入用于字符串匹配的模式或用于范围过滤的值范围。在使用模式匹配时,可以根据模式是包含通配符还是正则表达式设置复选标记。
- 按行号过滤:如果选择了“按行号过滤”,则设置开始行号和结束行号,系统将按指定行号过滤。
- 按RowID过滤:如果选择了“按行ID筛选”,则指定一个正则表达式,该正则表达式与每一行的行ID匹配。
举例:
-
需求:现有一个某年级某班的学生成绩表,需要筛选过滤出语文成绩在90-100之间的学生名单。
-
操作步骤:参见视频。
行过滤(基于时间) ¶
功能:选择指定的时间类型列,与日期和时间选择框内规则,两个维度结合过滤数据。
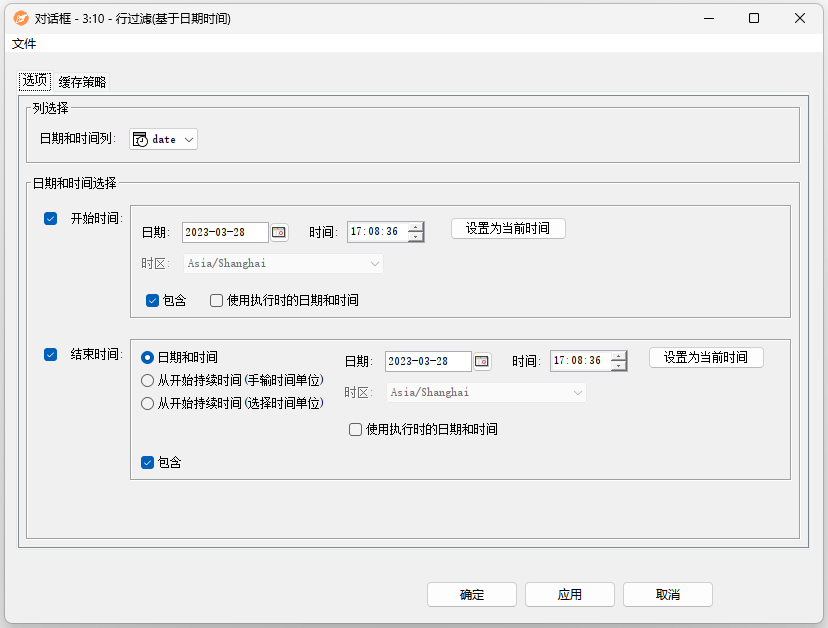
配置界面功能说明:
配置-选项:
- 列选择:
- 日期和时间列:将根据所选列的日期/时间列字段进行筛选。
- 日期和时间选择:
- 开始时间:开始日期/时间决定了过滤器的下限。它是可选项,即如果没有定义起始值,则没有下限。
- 结束时间:结束日期/时间决定了过滤器的上限。它是可选项,即如果没有定义结束值,则没有上限。
排名 ¶
功能:对于每个组,根据所选的排名属性和排名模式计算个人排名。
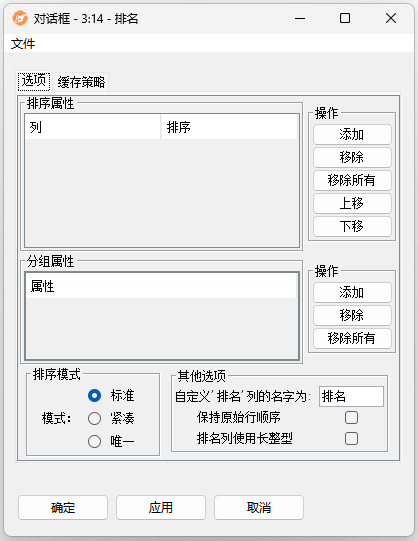
配置界面功能说明:
设置:
- 排序属性:排序属性可以通过相应的按钮添加,删除和优先级。为了更改所选的属性,可以单击属性的名称,打开一个包含所有可用属性的下拉菜单。排行表中的第一个属性具有最高的优先级,所有以下属性只有在表中更高的属性中存在关联时才会发挥作用。可以通过单击表中的一个属性名称并在下拉菜单中选择所需的属性来选择属性。对于每个属性,可以选择是升序计算还是降序计算。为此,单击相应的排名属性的顺序,并选择所需的值。
- 分组属性:排序属性可以通过相应的按钮进行添加和删除。可以通过单击属性名称并在下拉菜单中选择所需的属性来选择属性。
- 排序模式:三种排序模式。
- 标准:在排名属性中具有相同值的行将收到相同的排名,而下一个具有不同值的行将收到根据具有相同排名的行数增加的排名。因此,排名存在差距。
- 紧凑:在排名属性中具有相同值的行接收相同的排名,但具有下一个不同值的行接收的排名仅增加1。
- 唯一:排名是连续的,即使在排名属性中具有相同值的行也会获得唯一的排名。
- 其他选项:
- 自定义“排名”列名称:用户可自定义排名列列名。
- 保持原始排序:如果勾选该选项,则保留原来的行顺序。只有在确实需要时才应该检查此选项,因为行顺序的恢复是运行时密集的。
- 排名列使用长整型:如果排名属性为Long类型,则选中此选项。建议仅在表数据非常大的情况下使用此选项。
合并 ¶
功能:该节点连接两个表。输入端口0处的表是第一个输入表(顶部输入端口),输入端口1处的表是第二个表。具有相同名称的列被连接起来(如果列类型不同,则列类型是两个输入列类型的共同基础类型)。如果一个输入表包含另一个表没有的列名,这些列可以填充缺失值或过滤掉,即它们不会出现在输出表中。
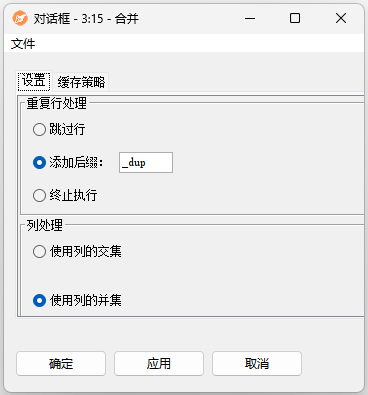
配置界面功能说明:
设置:
- 重复行处理:
- 跳过行:第二个表中出现的重复行标识符(RowID)不会附加到输出表。此选项相对而言占用大量内存,因为它需要缓存行id以查找重复项。此外,还需要完整的数据复制。
- 添加后缀:输出表将包含所有行,但是重复的行标识符用后缀标记。与“跳过行”选项类似,此方法也占用大量内存。
- 终止执行:如果遇到重复的行id,节点将在执行期间失败。此选项在检查惟一性时非常有效。
- 列处理:
- 使用列的交集:只使用出现在输入表的列。任何其他列都被忽略,不会出现在输出表中。
- 使用列的并集:使用输入表中所有可用的列。如果某些列缺少单元格,则用缺失值填充行。
数据排序 ¶
功能:该节点根据用户定义的条件对数据行进行排序。
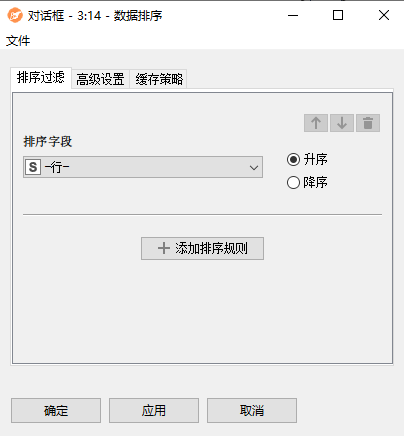
配置界面功能说明:
设置:
- 排序字段:选择表格数据中排序字段列名。排序字段值自定义升序/降序。
- 添加排序规则:允许通过添加额外的排序条件来进行排序。
- 高级设置:
- 在内存中排序:勾选该项,则在内存中排序,这需要更多的内存,但速度更快。如果输入表很大且内存不足,建议不要选中此选项。
- 缺失的单元格排序到列表的末尾:如果选择的缺失值总是放置在排序输出的末尾。这与排序顺序无关,即如果按升序排序,则认为它们比非缺失值大,如果按降序排序,则它们比任何非缺失值小。
删除重复行 ¶
功能:该节点可以从输入表中删除所有重复的行,只保留惟一的和所选的行。
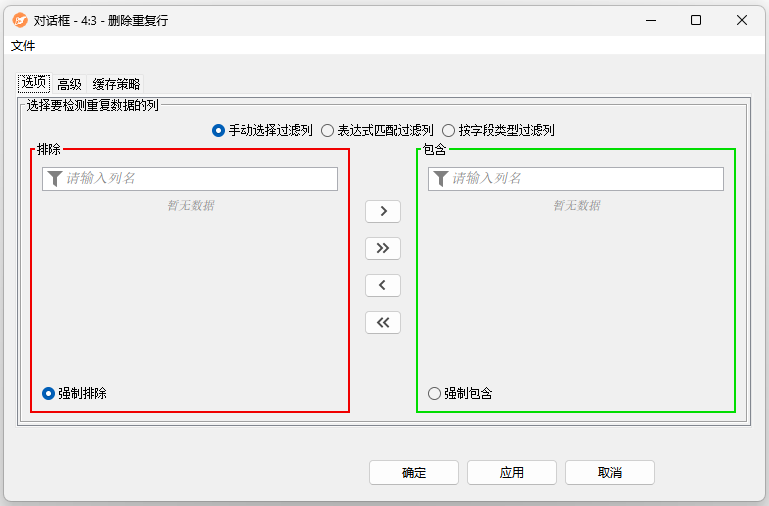
配置界面功能说明:
配置-选项:
- 选择要检测重复数据的列:允许选择标识重复项的列。可以“手动选择过滤列”/“表达式匹配过滤列”/“按字段类型过滤列”。未选中的列在“高级”选项卡中选择并配置。
配置-高级:
- 重复行:删除重复的行,或者只保留惟一的选定行。
- 选择行:定义为每组副本选择哪一行。
- 附加选项:
- 内存计算:如果选择,计算速度是利用工作内存(RAM)。所需的内存量比常规计算要高,而且还取决于输入数据的量。
- 保留行顺序:默认勾选,输出表中的行将按照与输入表相同的顺序排序。
行转列 ¶
功能:使用选定数量的列在给定输入表上执行旋转以进行分组和旋转。

配置界面功能说明:
配置-设置:
- 分组:
- 分组设置:选择一个或多个列的列名,作为行。
- 旋转:
- 旋转列:选择创建主列的一个或多个列。
- 忽略缺失值:忽略主列中缺少值的行。
- 附加总数:附加对所有选定的主列一起执行的每个聚合的总体主列总数。
- 忽略域:忽略域,只使用输入数据中可用的可能值。
- 手动聚合:从可用列列表中选择一个或多个列进行聚合。在表的聚合列中更改聚合方法。您可以多次添加同一列。要更改多个列的聚合方法,请选择要更改的所有列,用鼠标右键打开上下文菜单并选择要使用的聚合方法。勾选缺失的框以包含缺失的值。如果聚合方法不支持缺失值,则可能禁用此选项。
- 高级设置:
- 列名:结果主列的名称取决于所选的命名模式。
- 聚合名:结果聚合列的名称取决于所选的命名模式。
- 按字母排序:按字典顺序对属于同一个逻辑组(即支点(聚合)、组和总体总数)的所有列进行排序。
- 每组最大唯一值:定义每组唯一值的最大数目,以避免内存过载问题。在计算过程中,所有具有更多唯一值的组都被跳过,并在相应列中设置一个缺失的值,并显示一个警告。
- 值分割符:聚合方法(如concatate)使用的值分隔符。
- 在内存中处理数据:在内存中处理表。需要更多的内存,但是速度更快,因为在聚合之前不需要对表进行排序。内存消耗取决于惟一组的数量和所选的聚合方法。输入表的行顺序将自动保留。
- 保持原始的顺序:保留输入表的原始行顺序。可能会导致更长的执行时间。如果选择了内存中的进程选项,行顺序将自动保留。
- 启用高亮:如果启用,对组行进行高亮显示。
日期时间偏移 ¶
功能:该节点可将给定的时间格式数据,按照配置的时间偏移规则,进行时间值变更。
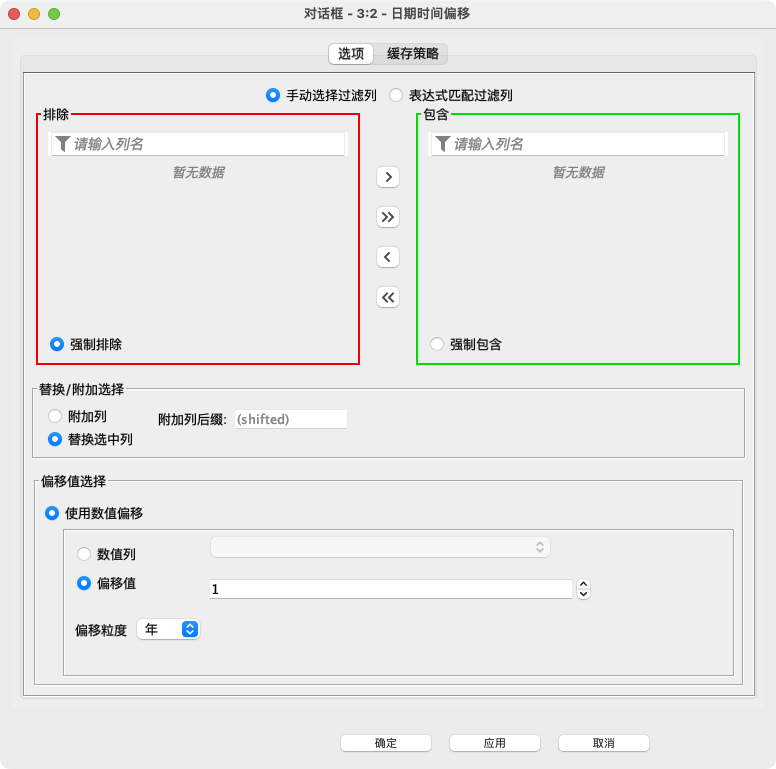
配置界面功能说明:
配置-选项:
- 过滤列选择:可选择手动选择过滤列或者表达式匹配过滤列。选择需要进行时间调整的字段。
- 替换/附加选择:
- 附加列:所选的列将被添加到输入表中。附加列的后缀可以在右边的文本字段中提供。
- 替换选中列:所选的列将被新值替换。
- 偏移值选择:根据数值偏移
- 数值列:选择以从数值列中选择移位值。参考日期或时间将加上一个正数,减去一个负数。
- 偏移值:选择插入一个整数作为固定移位值。参考日期或时间将加上一个正数,减去一个负数。
- 偏移粒度:数值的粒度(年、月、周、天、小时、分、秒、毫秒、纳秒)。
大小写转换 ¶
功能:该节点将英文字母进行大小写转换。
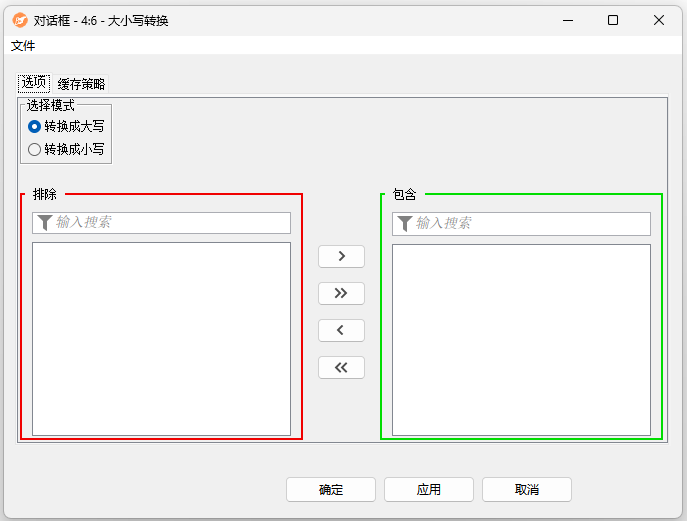
配置界面功能说明:
配置-选项:
- 转换成大写:将选定的字符串列转换为大写。
- 转换成小写:将选定的字符串列转换为小写。
行分割 ¶
功能:该节点主要功能是将数据按指定规则经过分割。
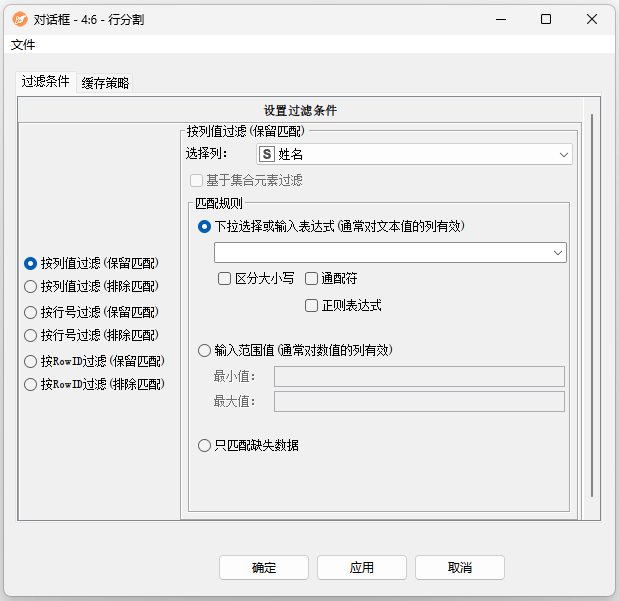
配置界面功能说明:
配置-设置:
- 按列值过滤:
- 选择列:用户可选择需要根据某一个字段去分割数据。
- 匹配规则:下拉选择或输入表达式(通常对文本值的列有效)。
- 例如:选择列为“姓名”,则此处可手动选择某个姓名去分割数据,或者写入表达式。 表达式规则:如填写" ^foo.** "。表示" ^ foo. "匹配任何以“foo”开头的内容。'^'字符表示单词的开头,' . '点匹配任何一个字符,''星号表示允许前一个字符的任何数字(包括零)。填写"[0-9] ",**表示匹配任何数字字符串(包括空字符串)。[ ]定义一组字符(它们可以单独添加,如[0123456789]或按范围添加)。这个集合匹配集合中包含的任何(一个)字符。
- 按行号过滤:用户可指定起始行和结束行,按选择的行号范围,分割数据。
- 按RowID过滤:用户可指定一个正则表达式,该正则表达式与每一行的行ID匹配。